Content migration - Structure of a migration


Introduction
In the previous post we talked about how to carry out an analysis and a migration plan for a content migration in drupal. In this second post we will bring that analysis into code.
What is migrate API
The Migrate API provides services for migrating data from a source system to Drupal 8. The set of modules making up Migrate API are:
- Migrate: It is the one providing the general use of migration framework.
- Migrate Drupal: It helps and allows us the migrations from D6 and D7 to D8 or later.
- Migrate Drupal ui: It provides us an user interface to perform migrations.
Migrate API is based on extracting, transforming and loading (ETL) processes.
- The data extraction phase is where the source plugin is used and with it, we reference their support and data set. They can be for example CSV, MySql, JSON, XML files, etc.
- The data transformation phase is where you make use of transformation extensions (process plugins). The purpose of this phase is the treatment and processing of individual data such as concatenate, capitalize, extract, skip a field if it is empty, add a default value, etc.
- The data loading phase is where the destination plugin is used and its purpose is to create entities in drupal. These can be: nodes, content types, taxonomies, users, etc.
Additional tools
As additional tools to facilitate the development and launch of migrations, the following modules are used:
Migrate plus
This contributed module (https://www.drupal.org/project/migrate_plus) provides us with extensions to the core framework of our migration. The features of this module are:
- Defining migrations and their plug-ins as configuration entities, allowing flexible loading, modification, and saving.
- It allows us to create migration groups to organize our migrations so that they are grouped to launch them later.
- New PREPARE_ROW event which allows us to modify the source data before processing begins.
- Plugins for data processing in configuration files: : entity_lookup, entity_generate, file_blob, merge, skip_on_value, str_replace o transliteration.
- Plugins for the destination of data in the configuration files:
- Table: it allows you to migrate data directly to an SQL table. - Plugins for the source in the configuration files.
- SourcePluginExtension - An abstract class that provides a standard mechanism for specifying identifiers and fields from a source through configuration.
- Url - A source plugin that supports file-based content.
The source and destination map or relationships are saved at the database table level, as it is the case with the messages of possible problems found at the migration launch.
Migrate tools
This contributed module (https://www.drupal.org/project/migrate_tools) provides us tools to execute and manage migrations. It provides us with a series of drush commands to interact with migrations such as migrate:status or migrate:import.
In the following post we will see how to manage migrations with this module.
Other modules
There are other contributed modules that offer extra functionality to drupal migrations. Some of them are listed below:
- Migrate Source CSV: Allows you to use CSV files as data support.
- Migrate Google Sheets: To migrate from Google spreadsheets.
- WordPress Migrate: To carry out migrations from a wordpress cms.
- Migrate Process S3: It offers the "s3_download” process plugin to extract files from S3 to the migration.
- ...
Structure of a migration
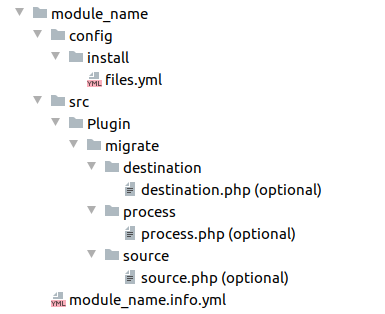
Module of a migration
As mentioned in the previous post about content migration, automatic migrations have quite a few limitations, for this reason we are going to focus on custom migrations. To do this, we must create a custom module that will define its dependencies in the .info file (migrate, migrate_plus, migrate_tools, etc.), the .yml configuration files and the definition of plugins if needed.
Connection to the source database
In case the source has a database as data support, for example in the case of a drupal 6 or 7 system, the connection must be added in the drupal settings.php file:
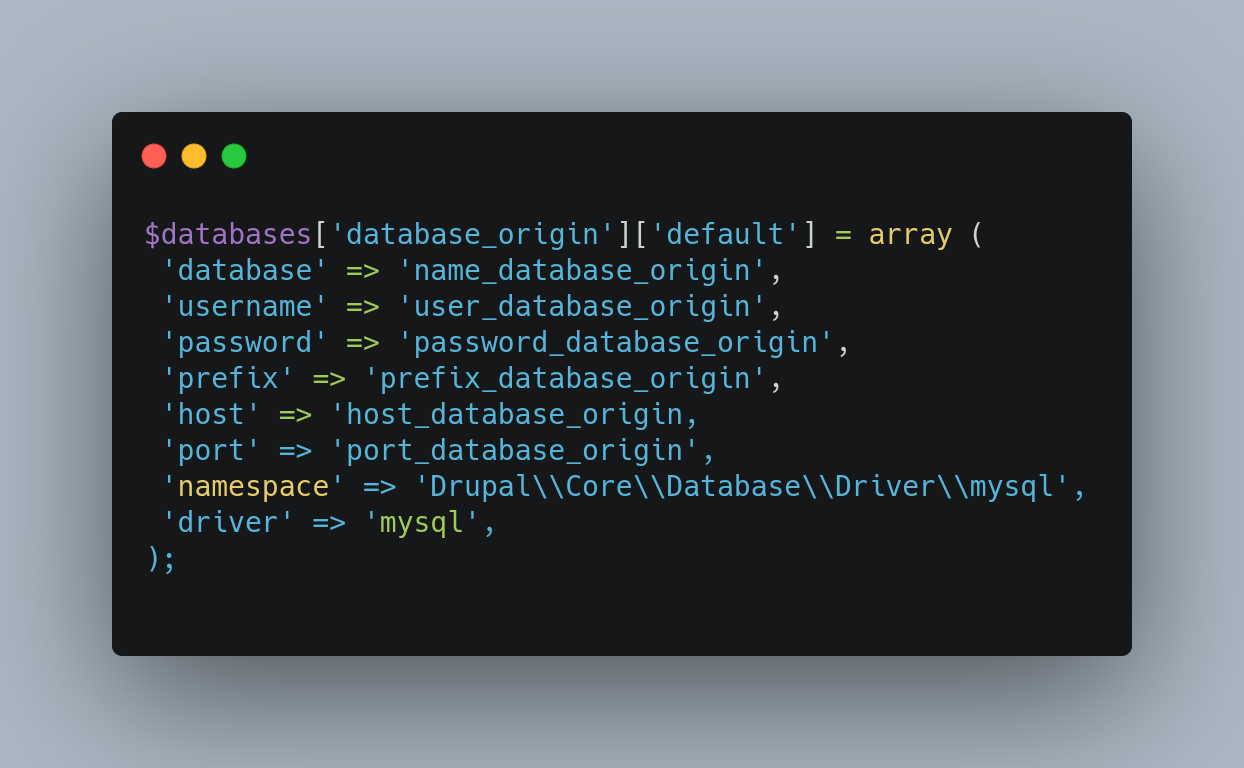
The key (database_origin) of the connection to the database will be the one referenced in the configuration file of the migration group, if it is the case that the key is called migrate, it should not be specified in the file.
Configuration files
Inside the config/install directory there will be the configuration files for each of the migrations that are going to be carried out and those for the migration group.
Group configuration file
As standardized by migrate plus, the nomenclatures of these files must be: migrate_plus.migration_group.[my_migration] .yml.
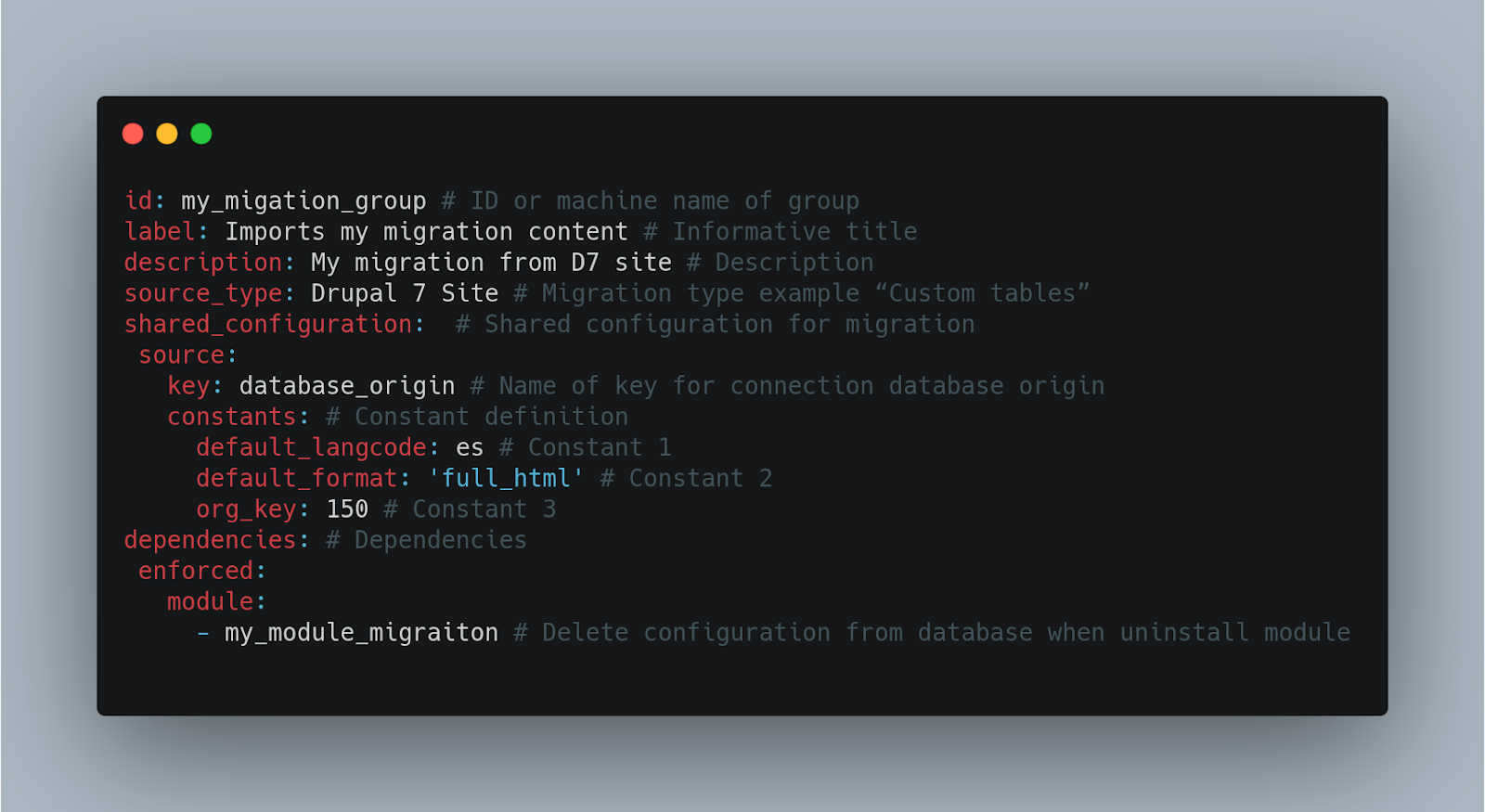
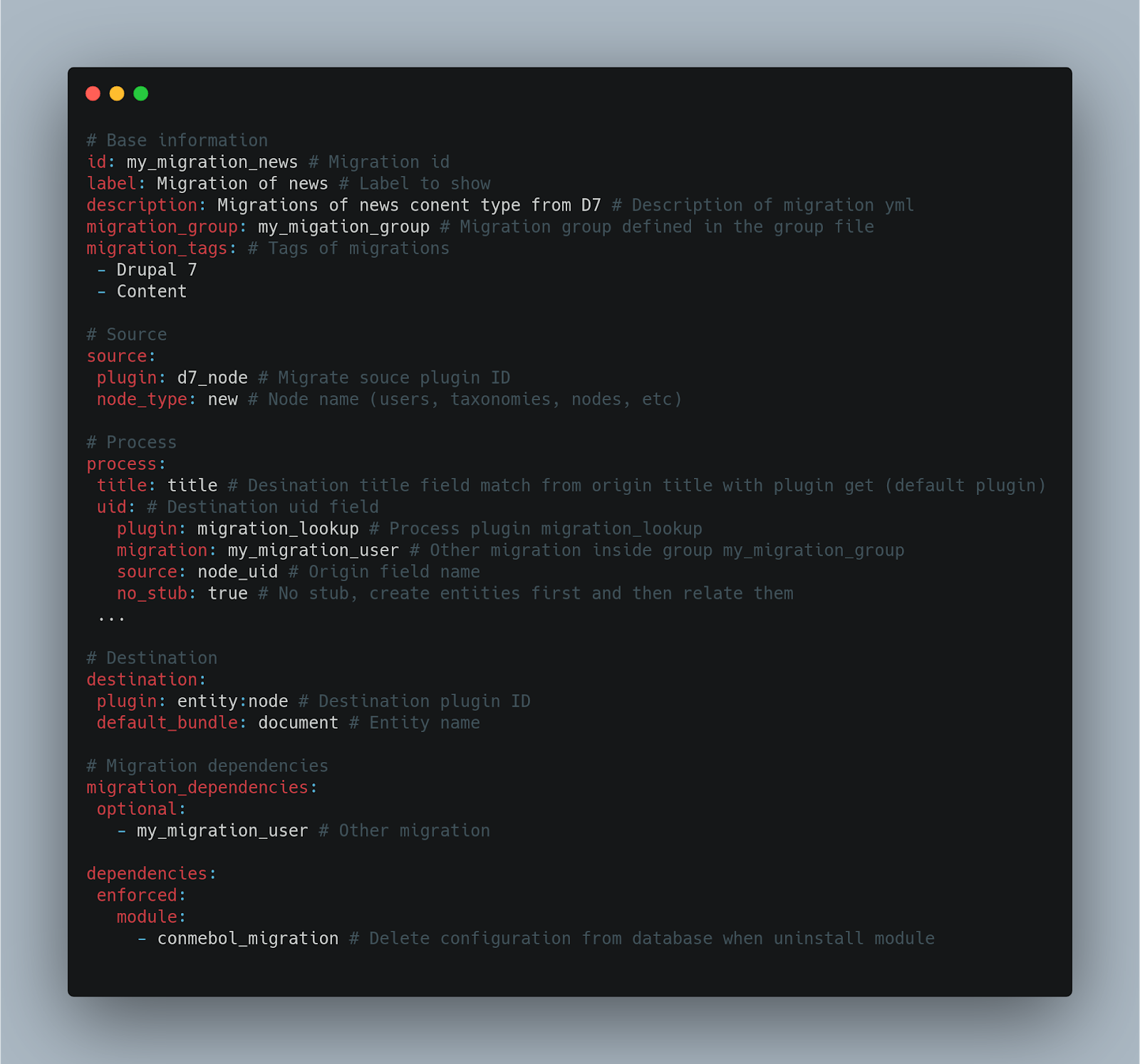
Configuration file of a migration
As standardized by migrate plus, the nomenclatures of this type of files must be migrate_plus.migration. [my_migration] _ [entity] .yml.
Most of the configuration files are already defined in drupal, either in the core or in contributed modules that require migrations for the transfer of information. We simply have to search within each module for the migrations directory and we will find it. Here are some of these:
- User migration: core/modules/user/migrations/d7_user.yml
- Content type migration: core/modules/node/migrations/d7_node.yml
- Taxonomy terms: core/modules/taxonomy/migrations/d7_taxonomy_term.yml
- Google analytics: modules/contrib/google_analytics/migrations/d7_google_analytics_settings.yml
- Pathauto: modules/contrib/pathauto/migrations/d7_pathauto_patterns.yml
If we have the need to migrate users, for example, we simply duplicate the d7_user.yml and modify what we need to adapt it to the new data model of the corresponding entity. Time and experience will do the rest.
Once our module is installed, for each of these files we will find two tables at the database level:
- migrate_map_ [id_migration]: It contains the relationship of source identifiers (sourceid) with destination identifiers (destid).
- migrate_message_ [id_migration]: It contains the possible error messages that arise during the migration.
The sections and the organization that make up these configuration files are those that we will see below.
Base information
Information and identification about a specific migration. Migration identifier, label to display, migration group are some of the properties that make up this section.
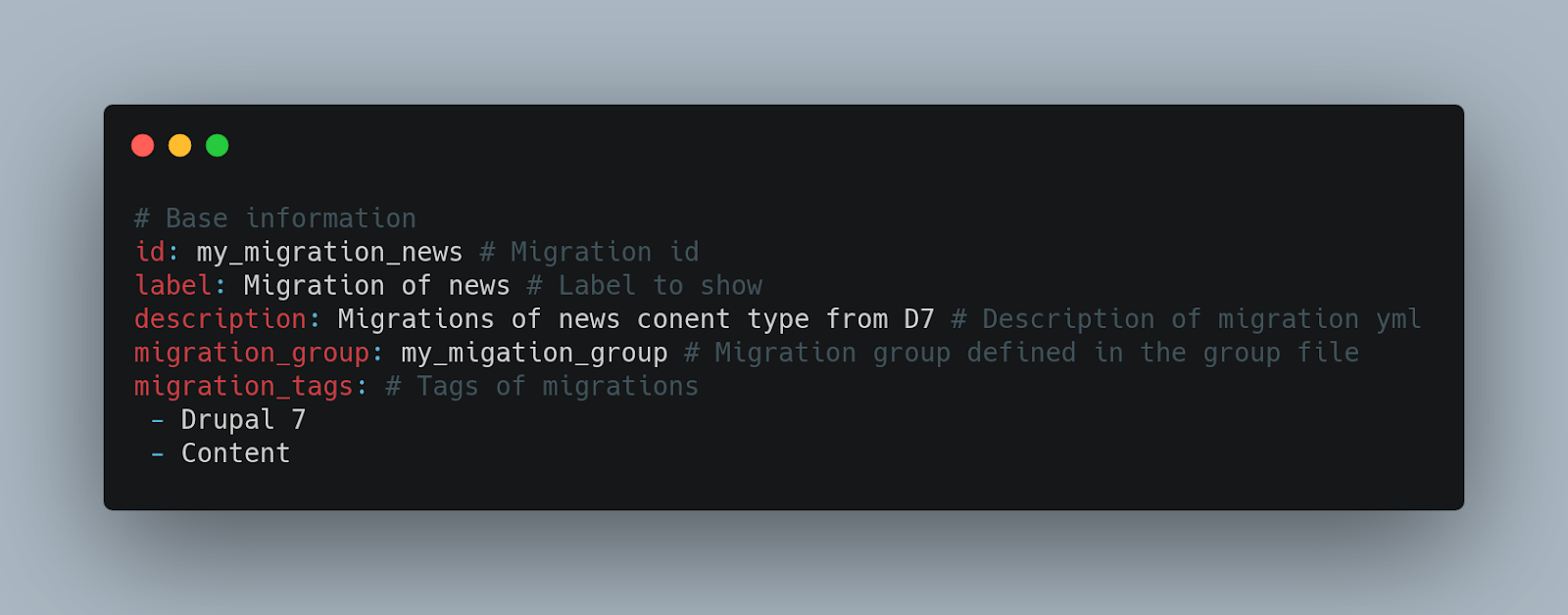
Data sources (Source key)
They are responsible for obtaining the data from the source or origin. This would be the source entity that we are going to import into our drupal system, a content type, a taxonomy, users, etc.
There are defined plugins that extend from SourcePluginBase:
- File migration: /core/modules/file/src/Plugin/migrate/source/d7/File.php
- User migration: /core/modules/user/src/Plugin/migrate/source/d7/User.php
- Taxonomy migration: /core/modules/taxonomy/src/Plugin/migrate/source/d7/Term.php
- Node migration: /core/modules/node/src/Plugin/migrate/source/d7/Node.php
There are modules that extend from other sources:
- Migrate Source CSV
- Migrate Google Sheets
- WordPress Migrate
- ...
Other properties:
- track_changes: when running a migration, this property updates previously migrated nodes that were updated at source after migration. Not to be confused with the --update flag, the latter will update any migrated node.
- translations: For multi-language migrations.
- constants: Constants for use in migration.
All these plugins are located inside each module in the directory ‘src / Plugin / migrate / source’ and can be declared new or extend existing ones.
More information about this section can be found at the following link: https://www.drupal.org/docs/8/api/migrate-api/migrate-source-plugins
Here is a series of examples to better understand the data source:
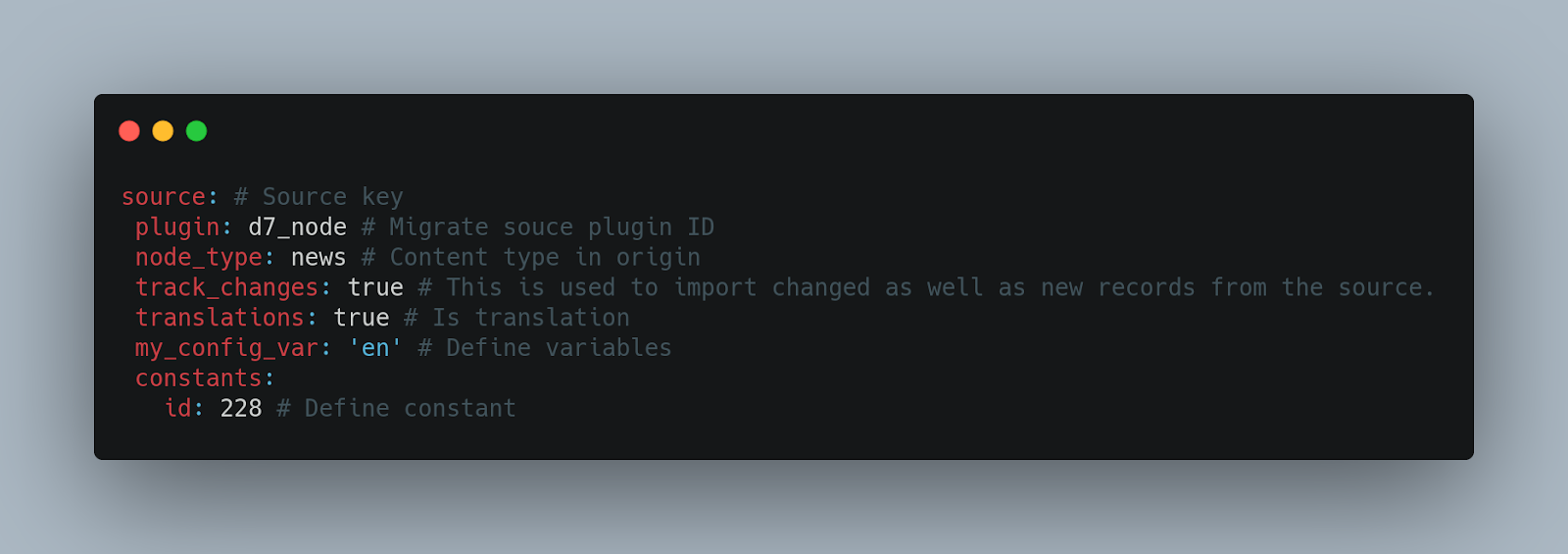

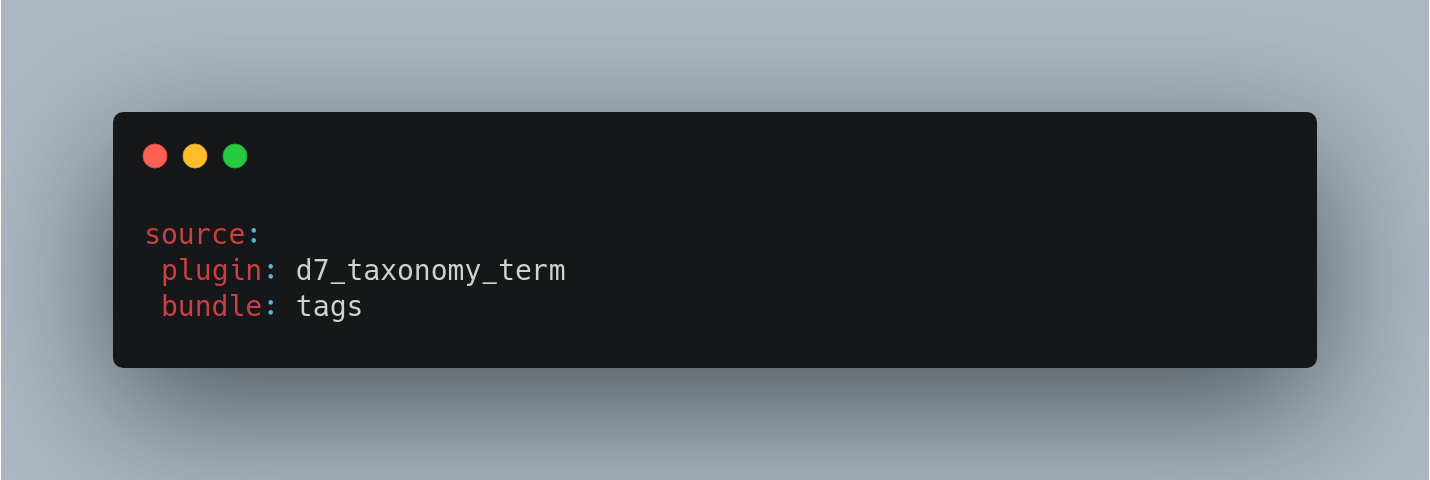
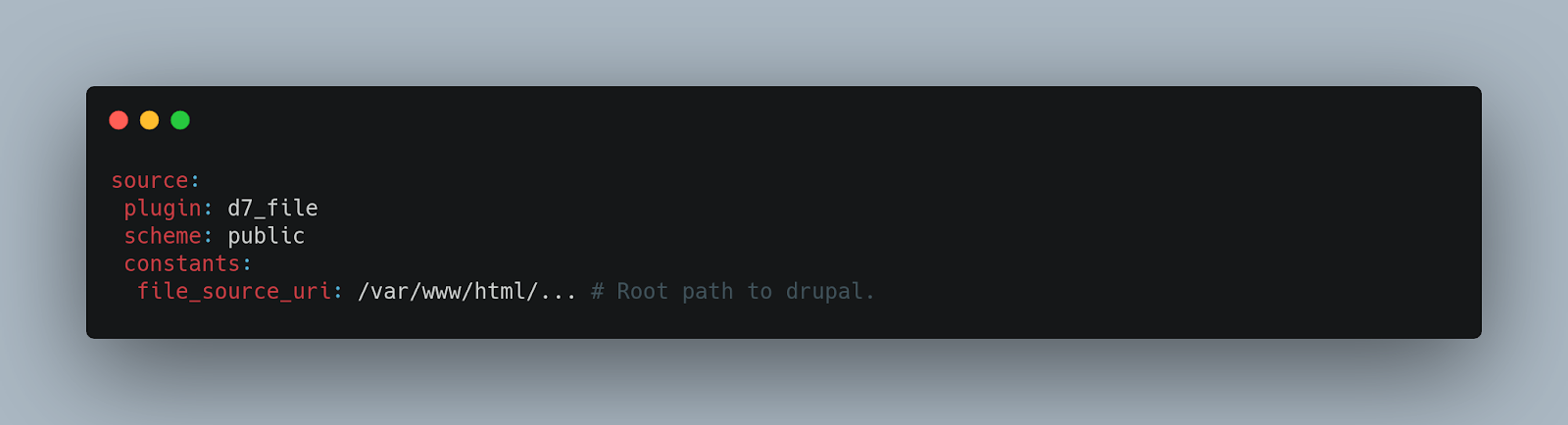
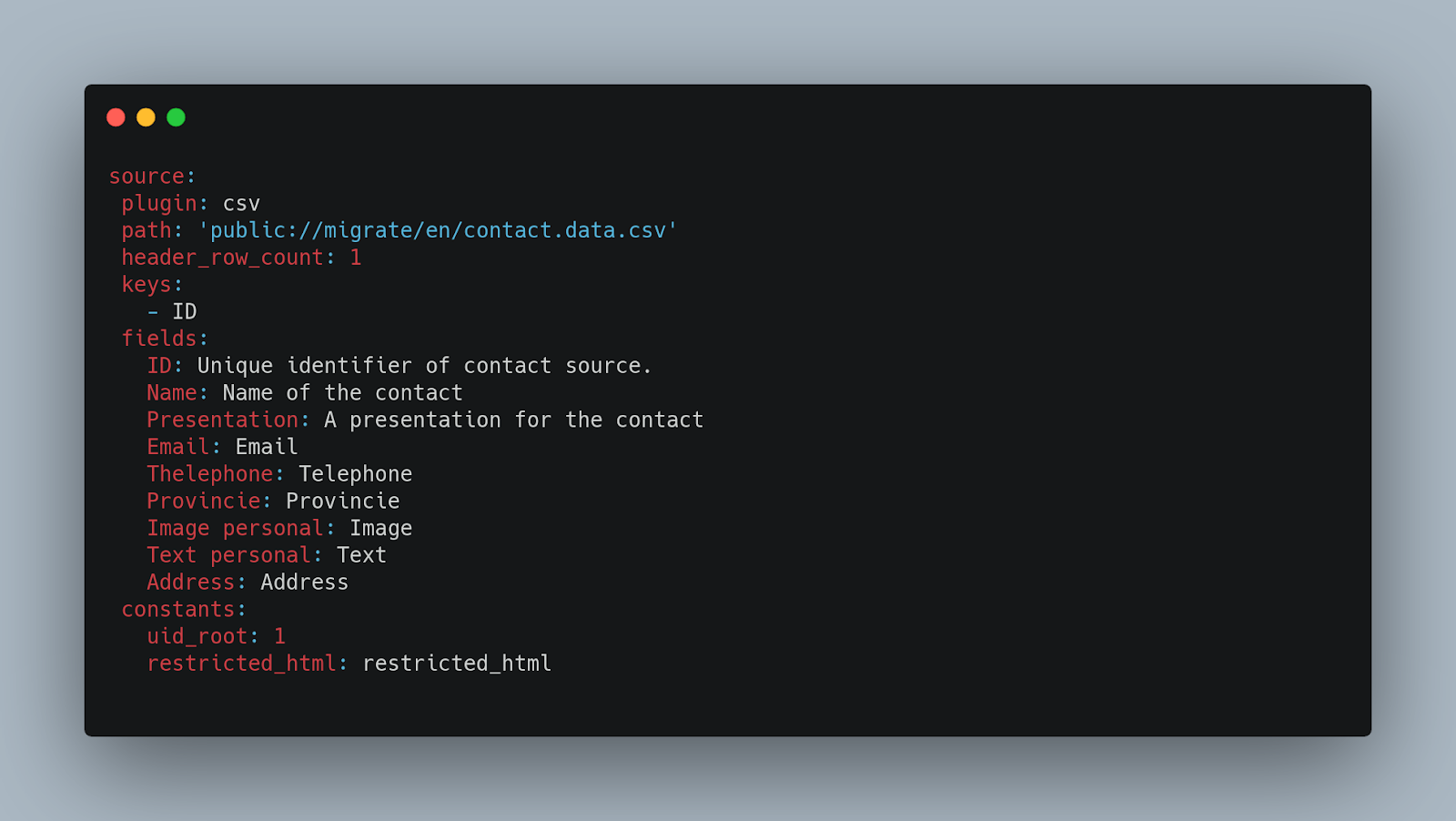
Data processing (Process key)
It describes property by property how the destination will be constructed from the source data. The value of the process key is an associative array, where each key is a target property. The values associated with each key describe how the target value is created. In short, it is where the source data is processed and treated and therefore where the migration has the greatest workload.
There are plugins that extends from the ProcessPluginBase:
- Get (default)
- Callback
- migration_lookup
- sub_process
- concat
- ...
Other attributes:
- Copy of '@var' values: Definition of variables to use within the process section.
- Pipelines or pipes - - - - -: They chain plugins to process the data for one purpose.
- no_stub: It solves the problem of who is born first, the chicken or the egg? This property is used for circular references or relationships. For example, if we have an article node that has the same article content type related, we can use the no_stub: false property. For the same case, if when migrating an article with identifier 1 that has an article with identifier 3 related and the latter has not yet been migrated and therefore does not exist in the destination, migrate API adds this content to the destination as stub, creating thus, a node in drupal of the type that corresponds to the destination and reserving an identifier that will be assigned as related to the node with identifier 1. As soon as the migration passes through node article 3, it will update the references in the node that it has reserved as stub.
All these plugins are located or must be located within each module in the directory ‘src/Plugin/migrate/process’ and can be declared new or existing extensions.
In the following link you can find more information about this section: https://www.drupal.org/docs/8/api/migrate-api/migrate-process-plugins
Below you can find a series of examples to better understand the data processing:
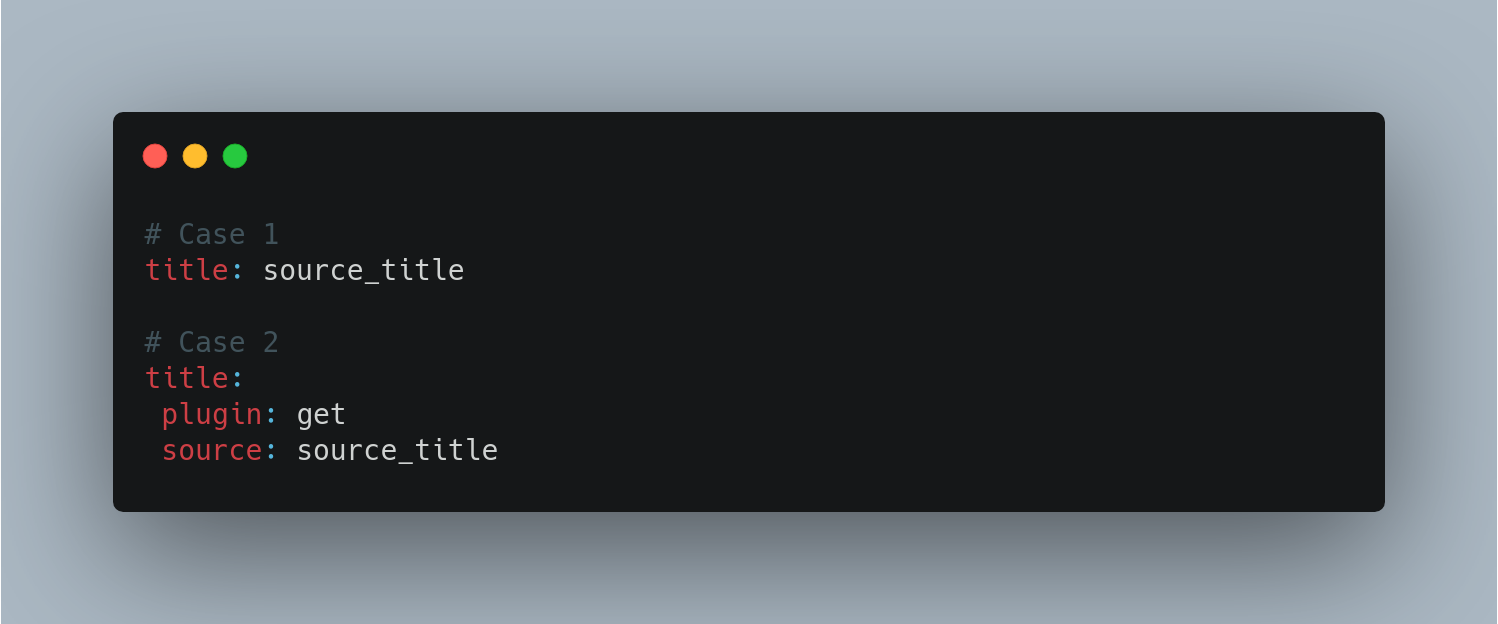
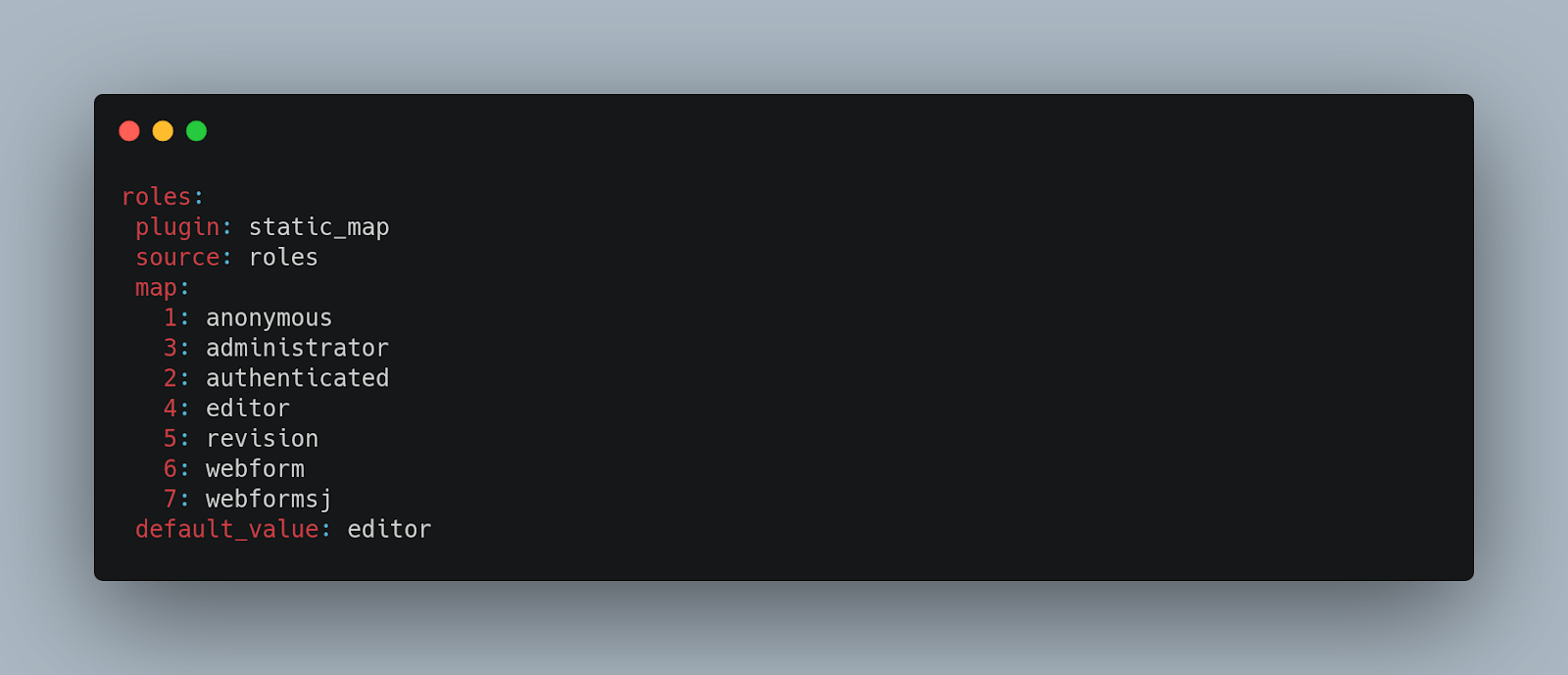
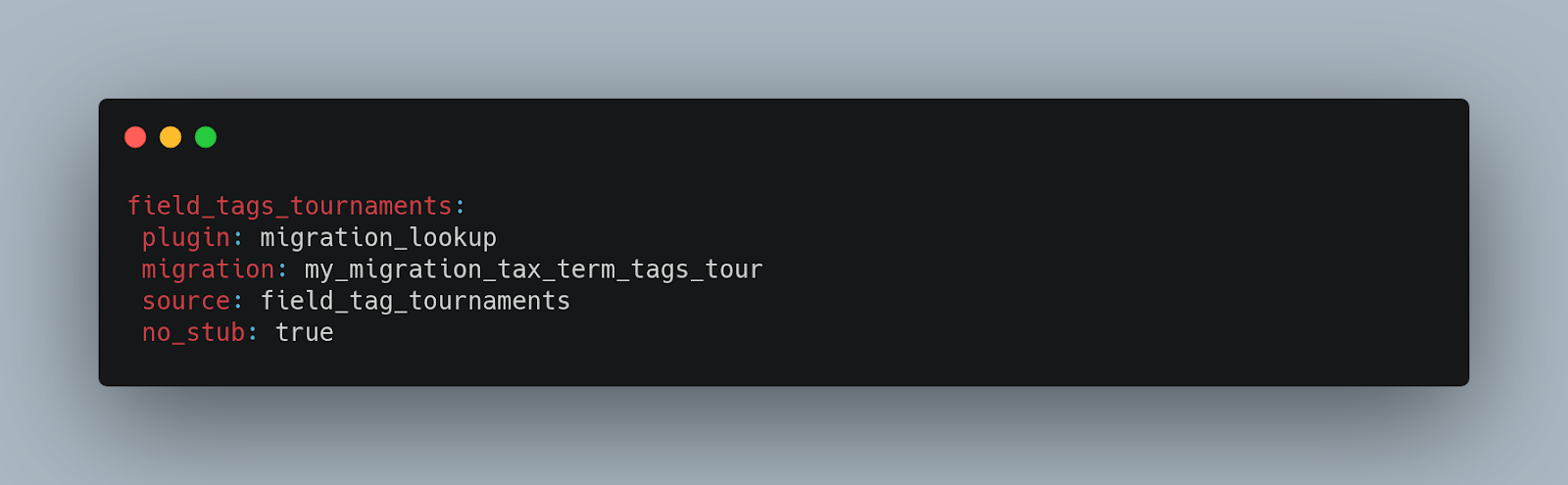
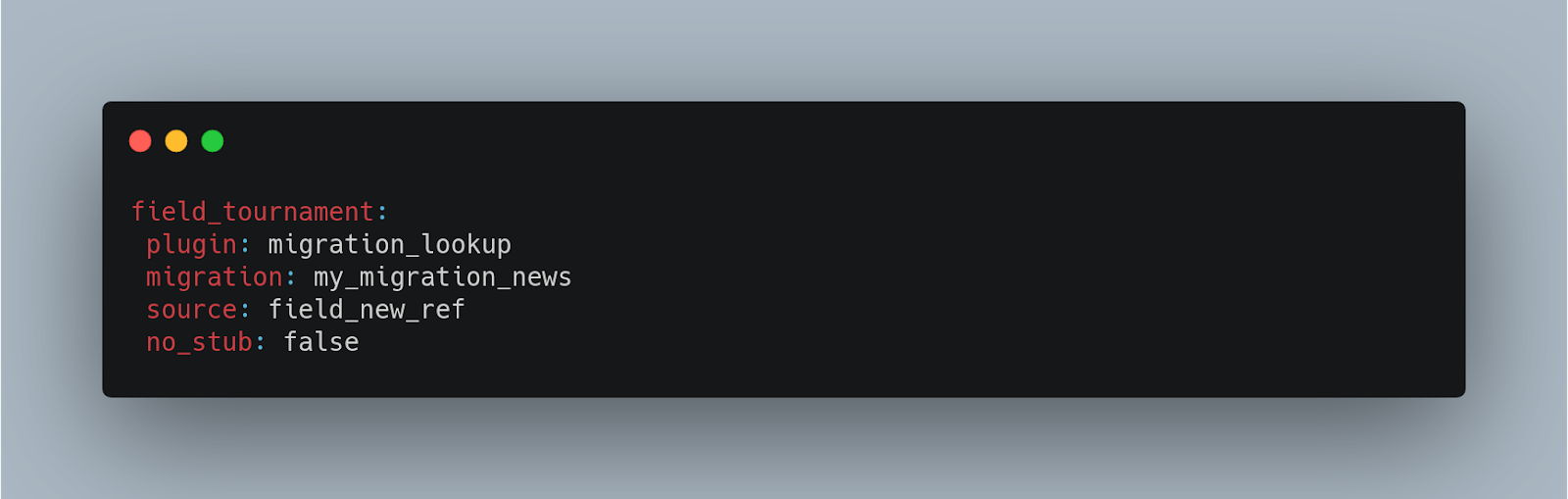

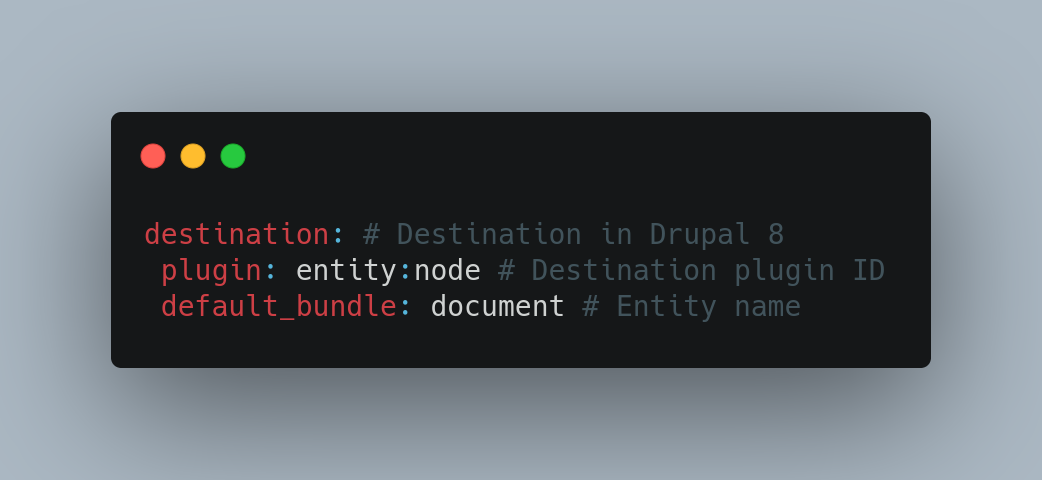
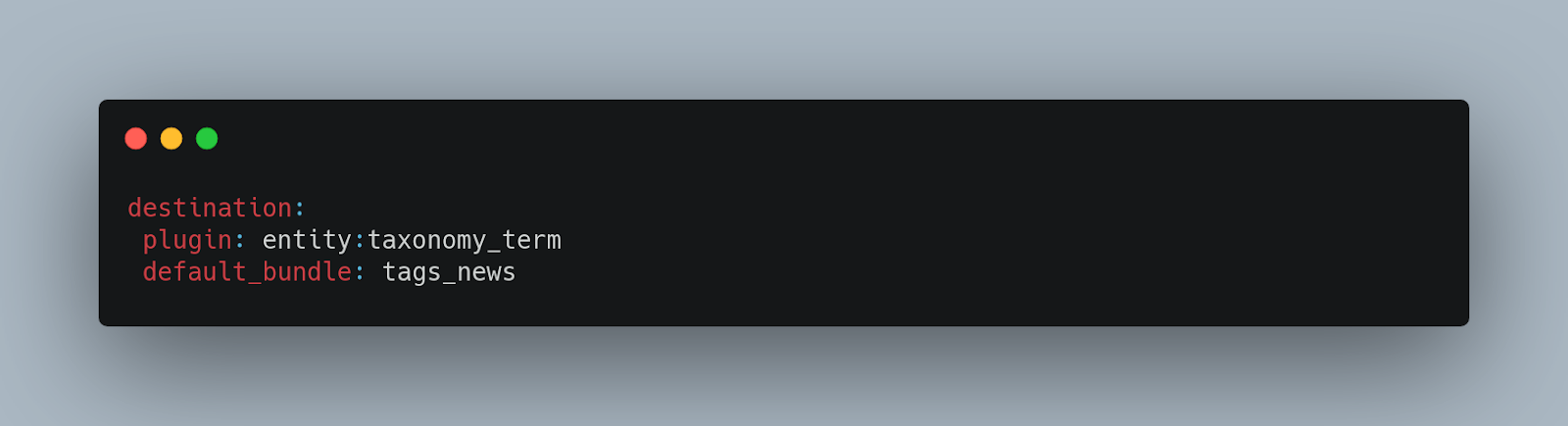
Destination (Destination plugins)
The Migration API Destination Plugin indicates what type of Drupal entities are created. These can be of two types:
- Content entities: nodes, users, taxonomy terms, files, etc.
- Configuration entities: content type, field definitions, etc.
The target entity type is usually defined as for example entity: entity_type and entity: node
There are defined plugins that extend from DestinationBase:
- entity:entity_type
- entity:taxonomy_term
- entity:user
- entity:file
- entity:media
- ...
A property for the migration of content translations is “translations: true” in which we are indicating that what we are going to create at destination is a translation.
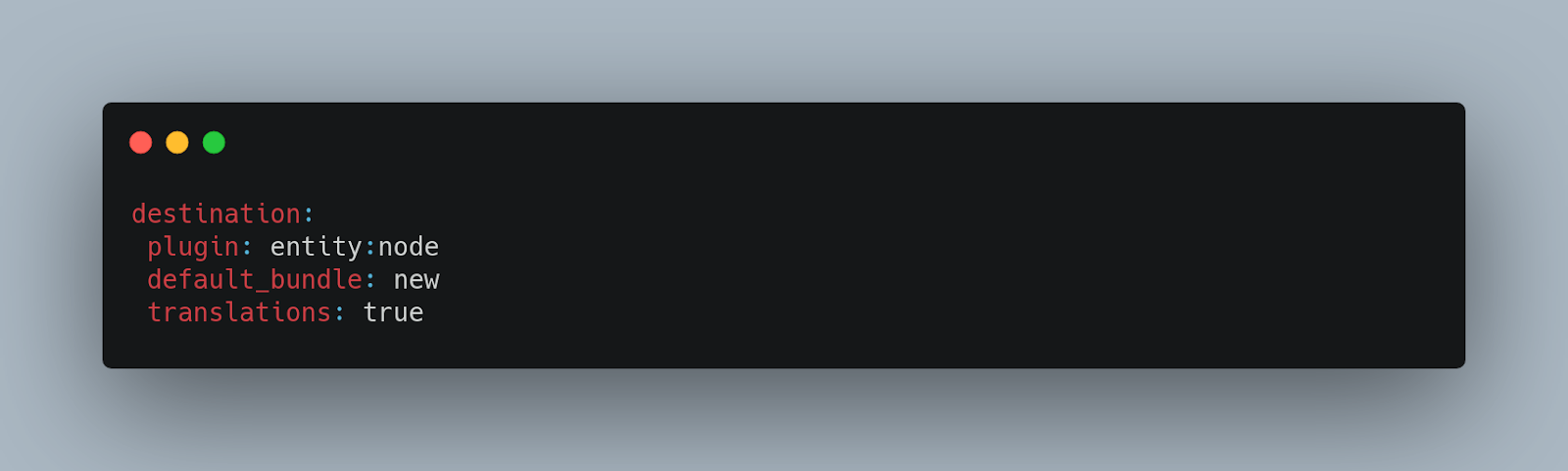
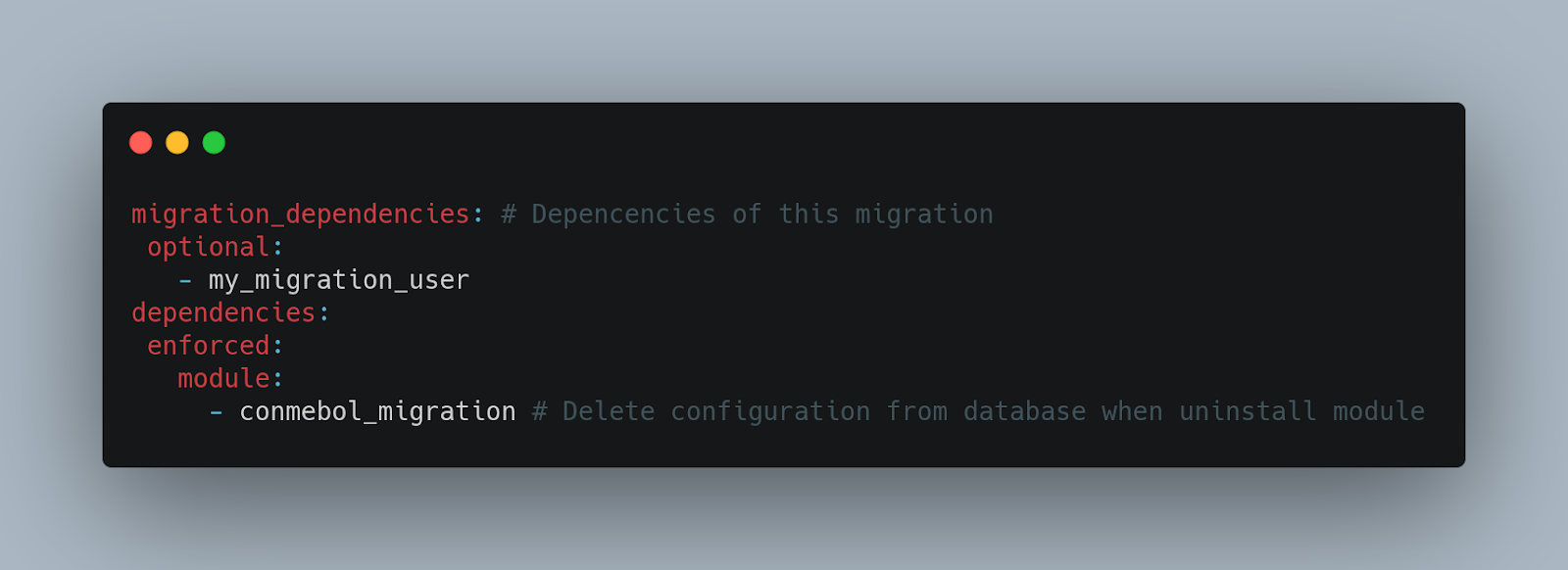
Dependencies
In the migration_dependencies key, the dependencies that exist within the process key of the migration file will go. These refer to related migrations that can be optional or required and will be executed before the ones with the dependency. Therefore, there will be as many dependencies as there are migrations in this section. If the dependencies are optional, we can launch the migration regardless of whether the dependency is migrated, if it is required, the dependency must be migrated.
Regarding the "dependencies" property, the name of the migration module itself is added to the file so that when it is uninstalled, it removes the configuration at the database level.
Conclusions
To conclude, we point out that the main things that this post attend to are the following:
- Necessary dependencies and modules.
- Structure of the migration module.
- Configuration files for the group and for migrations.
- Sections of a migration.
- Use of plugins.
In the next post we will see how ETL works through plugins and how to create new ones and extend these.